


看到 y1 情況下 , 機率分佈其參數會是 $ \theta_1 $ 的可能性高於$ \theta_2 $.
可能性的意義亦等同於 $ P( y_1 \mid \theta_1 ) > P( y_1 \mid \theta_2 ) $ ,
但如何找到最好的$ \theta $ 使其可能性達到最大,即機率 $ P( y_1 \mid \theta )$ 能達到最大, 此即為 最大概似估計 (Maximum Likelihood Estimation) 的目標。
若此機率模型為高斯分佈, 即什麼樣的參數 $(\mu, \sigma^2)$ , 能使 $ P(y_1 \mid \mu, \sigma^2)$ 最大.
若你的機器學習模型是預測一個高斯分佈的參數 $(\mu, \sigma^2)$
$$X \sim \mathcal{N}(\mu, \sigma^2)$$
$$f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{ - \frac{(x - \mu)^2}{2 \sigma^2} }$$
則你可以將對應答案 $y_1$ 丟入得出其機率,即 $$ f ( y_1 \mid \mu, \sigma^2) $$
若預測的參數夠好的話,則$f(y_1\mid \mu, \sigma^2)$ 應該要很大,若取Log 改以$$X \sim \text{Log-N}(\mu, \sigma^2)$$ 表示,值也會是大的。
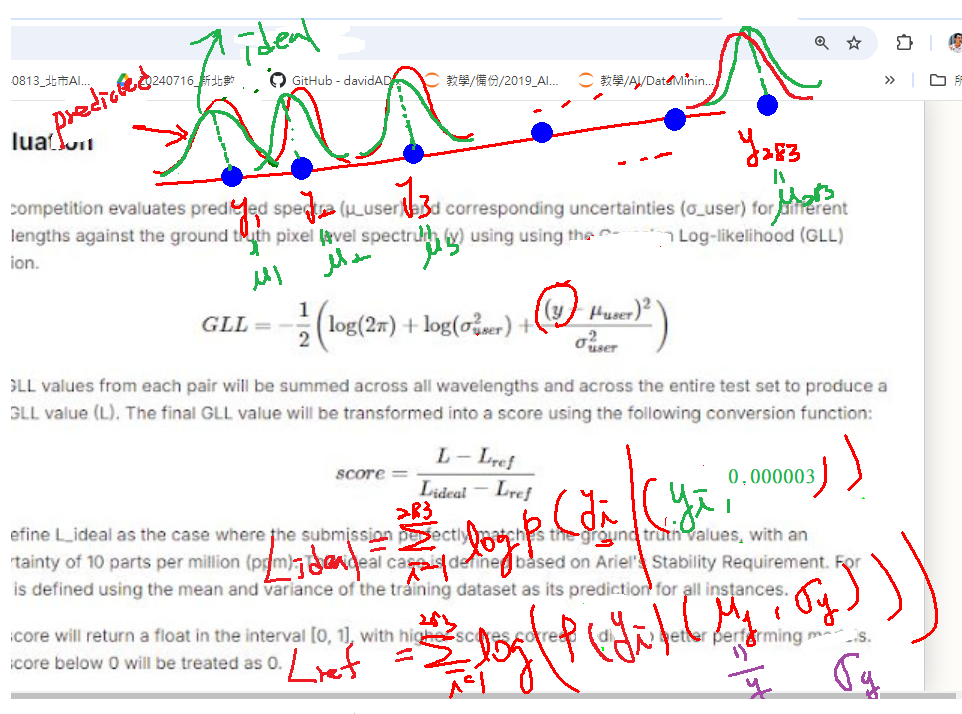
$$log(f(y_1\mid \mu, \sigma^2)) = -\frac{1}{2} \log(2\pi) -\frac{1}{2} \log(\sigma^2) - \frac{(y_1 - \mu)^2}{2 \sigma^2}$$
此式子的最大值為 y1=μ . y1=μ 代表我們猜得夠準才能使機率值最大


若預測多組 $(\mu_1, \sigma_1^2), (\mu_2, \sigma_2^2),...,(\mu_n, \sigma_n^2)$
效能可以直接加總 $$f(y_1\mid \mu_1, \sigma_1^2) +f(y_2\mid \mu_2, \sigma_2^2)+...+f(y_n\mid \mu_n, \sigma_n^n)$$ , 或取log 值相加也可以。
$log(f(y_1\mid \mu_1, \sigma_1^2)) +log(f(y_2\mid \mu_2, \sigma_2^2))+...+log(f(y_n\mid \mu_n, \sigma_n^n))$ ---> 這就是 GLL (Gaussian Log Likelihood)
a^2))$$

沒有留言 :
張貼留言